Bluesky Frustrations — Part 2
February 24, 2024
On Thursday the Bluesky team announced that users now can host their own content on the network. This sent me on a tangent looking into the AT Protocol (atproto) again. It turns out that a good amount has changed since I last dug into things.
The announcement linked to a developer focused post which stresses that this is a work is in-progress and not really ready for prime time. This isn’t a knock against the announcement — the team is working in the open. However, after reading this I had several thoughts and questions.
It might be helpful to mention the “Bluesky and the AT Protocol: Usable Decentralized Social Media” white paper. It was published earlier this month and gives the fullest overview I’ve seen of atproto’s architecture. It helped me understand some of the technical decisions and trade-offs.
With that, the meat of the announcement is that users can now host their own Personal Data Server (PDS). This server allows for user authentication and data handling through atproto. There’s a sample server provided by Bluesky which can be hosted on fairly modest hardware. 1
The Bluesky team is up-front that the process of migrating to your own PDS could break things. They advise users against migrating their primary accounts. In the same document they also point out that the process is currently one-way only. This will likely change with time, but for now there’s no way to hand things back to Bluesky. It’s also a rather hands-on process: you need to join a Discord and request that your PDS be added to the network. Once you’re accepted, you’ll be kept up to date on Discord about changes and updates. Overall, things are kind of sketchy at the moment.
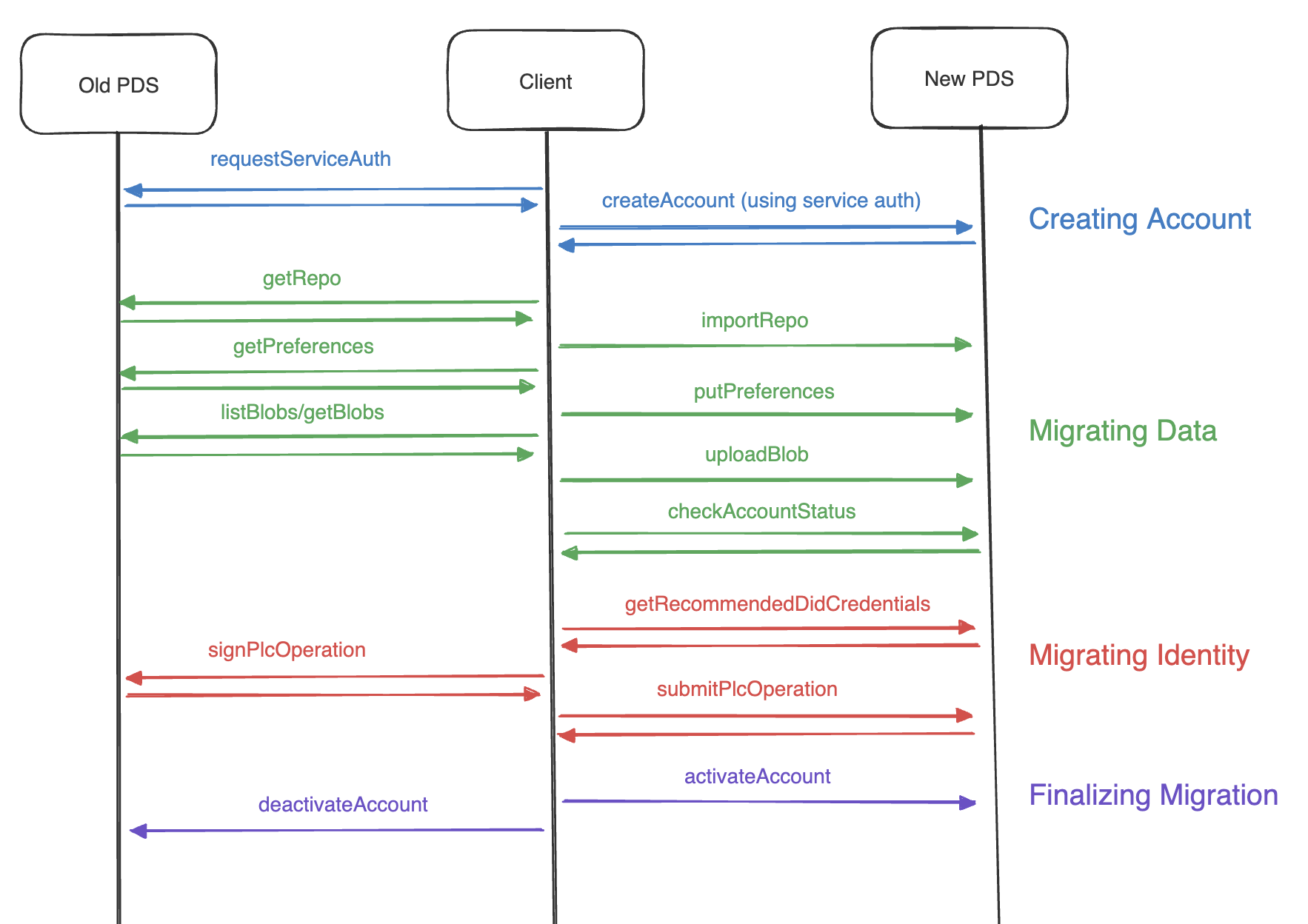
When I first started digging into the migration process, I was curious about how media files would be moved. Users have been able to export their content from Bluesky for a while now, but the file you get back is not exactly easy to work with. There is some documentation about the export format with code snippets to help you deal with it, but it’s a bit of a faff. It’s interesting to note that media files are not included in this export, and that you need to navigate the IPLD DAG-CBOR objects manually to get that content yourself.
It’s also interesting that the export documentation contains a privacy notice. Because of atproto’s architecture, almost everything is public. By design, you can easily use the export process to download any user’s data.
Looking at the account migration documentation again, there’s a diagram in the above link that shows the process of migrating. This seems to indicate that the server would get this content for you. Reading further down the page, it looks like this is something you need to do manually. There’s some sample code provided, but the document stresses that it shouldn’t be run as-is.
{kind=link}
On the whole, this is an interesting first step. But it also shows how early Bluesky is in the process of federation. PDS migration seems shaky at best, and will need a lot of work to get it to a point where most technical people would want to give it a shot.
While I was looking into the migration, I also spent some time digging into some previous frustrations with atproto. The first being the DID PLC (short for “placeholder”) method. One of my larger complaints about atproto is that it’s rather complicated. DID PLC is a a great example of that, and I recommend checking the white paper linked above for a good overview.
It was previously noted in the documentation that they wanted to replace this method “within the next few years”. This has been updated to say it will be supported indefinitely. The main reason the team wants to replace this method is that it’s centralized. If you want to resolve a did:plc id, you need to ask the server at https://plc.directory/ about it. It’s mentioned that Bluesky wants to make this decentralized eventually. This system is sort of like the DNS of the Bluesky platform, so I think this will take a while.
Another nitpick I had was around indexing and relays. As part of atproto, Bluesky operates an index of all actions (posts, replies, likes, etc.). To create this index, they crawl all PDSs and then act on any new content found in them. While the Bluesky team have made progress on allowing people to host their own content, there’s very little detail on how this system will be decentralized. Even once it can be, this is “firehose” level stuff. It will take a lot of compute/disk/network resources to spin up a new index.
This corner of the system is rather light on detail. There’s a bit of a description in the white paper, but I haven’t found technical details about how this system works. It also seemingly changed since I last wrote. There’s a Bluesky blog post from around that time which describes a “big world with small world fallbacks” system, but mentions of that seem to have been removed from the documentation. A previous version of the “Crawling Indexer” diagram has been replaced with a new one which removes the “Small-world” interconnects. I assume that means it isn’t part of the plan anymore?
{kind=link}
{kind=link}
After digging into this again, I’m still frustrated by the design trade-offs the Bluesky team is choosing. The system is currently centralized. I don’t doubt that they want fix this eventually, but I feel like they’re often given credit for having solved the problem already. Unless I’m missing something, decentralizing the did:plc and indexing systems will be extremely difficult.
It’s also still unclear how any of this will be monetized. They partnered with Namecheap last year to sell domains you can use as your username. I guess that’s something, but I doubt it’s going to make much money relative to infrastructure (let alone personnel) costs. My guess is that most people who’d use a domain as part of their username already have the domain they want to use. It seems like they have a good amount of runway, but I’d bet that the service will be less fun to use when investors start looking for a return.
I think people will be surprised by how little privacy there is on the service. Because of the indexing flow, all data currently must be public. As noted above, you can export any user’s data. You can also easily attach to the firehose of all new posts and also just literally download the whole thing. Again, this is all by design and not necessarily bad. I just think it might be surprising to many.
I’m personally a fan of ActivityPub. The standard has several issues, but the key benefit is that it’s quite straightforward. Even as atproto work moves forward, there are still a lot of unanswered questions. It feels like there’s a good deal of second-system effect going on. I’d still prefer my “team” win, but I’m curious to watch Bluesky/atproto develop.
-
Based on the provided specs, hosting the project on a Digital Ocean VPS would start at $18 USD/month. ↩